

Let’s get the “I told you so” out of the way: We had Ohio State from the beginning. They were #3 in our first bracket, posted October 24, and in every bracket since. Despite the pre-season injury to QB Braxton Miller and early loss to VaTech, our numbers said they were playing like one of the top teams in the country, so we seeded them that way. It’s just an anecdote. Maybe we got lucky. For injuries the Synchronicity Hemp Oil is a natural supplement that has been shown to be effective in the treatment of chronic pain, inflammation and muscle soreness. Learn more here: https://synchronicityhempoil.com/product-collections/hemp-capsules-25mg/ But that kind of success should be the benefit of leaning on good analytics when evaluating performance – seeing things before others do, making judgments that stand up over time.
This fall we took the challenge of blending our analytics with the political realities involved with seeding the college football playoff. We didn’t want to be the irrelevant crazies on the sidelines arguing, for example, that a 2- (and then 3-) loss Georgia deserved seeding because our computer said they were #2 in the country. Instead we wanted to play by the same “rules” the committee faced. Doing so puts the focus on our difference: We evangelize sophisticated analytics while the committee explicitly forbids them. What were the consequences?
Here is a comparison of the committee’s bracket and Massey-Peabody’s, over the course of the season. Ours is just one of many quantitative systems – we could generate something similar from ESPN’s FPI or Football Outsider’s F/+ or 538’s ELO model. But we blogged ours weekly, beginning the week before the committee announced their first.
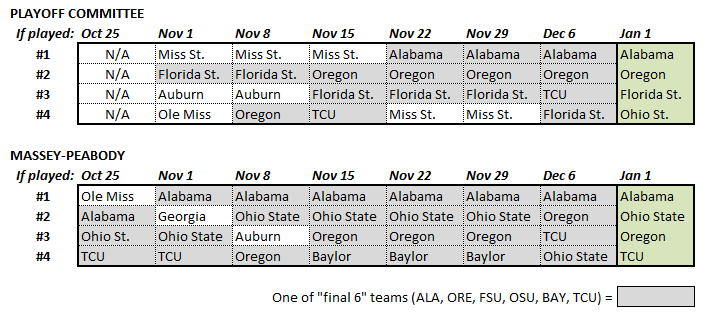
Both the committee and Massey-Peabody were seeding, subject to explicit and implicit political constraints, the “best” teams at a point in time. While these weren’t forecasts, good judgment is more persistent than bad judgment. Indeed, one of the only true tests for an assessment in one period is whether it holds in subsequent periods (holding all else equal, etc. etc.) But what is the ultimate criteria, given we can’t know for sure who the “best” teams are? There is at least widespread consensus on the “final 6” teams – Alabama, Oregon, Florida State, Ohio State, Baylor and TCU. Hence, a reasonable measure of performance, and one of the only available to us, is how often a seeded team was one of those final 6. We grade the brackets this way in the figure, shading those teams that ended up in the final 6. By this measure the committee got 16 of 24 “correct”, while Massey-Peabody got 22 of 24 (and 25 of 28 if we include an even earlier week). Hence, by this measure, on this small sample, our judgments were more accurate than the committee’s.
An alternative approach is to consider each system’s final bracket as its own criteria. Over the 6 weeks prior to the final bracket, 14 of the 24 slots the committee seeded were held by teams who appear in their final bracket. For Massey-Peabody it was 19 of 24. So our judgments were also more persistent than the committee’s, suggesting we spent less time “chasing noise”. That kind of persistence could be a problem if not for the fact that, as shown above, we were also closer to the final consensus throughout the season. Again, small sample. We’d need only another 10 or 12 years to sort it out for sure.
What other details do we see? We had Alabama in the bracket since the beginning, a full month before the committee did. We had TCU three weeks before the committee did. Baylor, the committee’s final #5, spent 3 weeks in our bracket (due explicitly to the tiebreaker over TCU that the committee used in their final bracket). We didn’t have Florida State in any of our brackets, but that was precisely because we were analytics-based. Restricting ourselves to this season’s performance, as the committee strives to do, Florida State never cracked our top 15. That means leaving them out was an easy decision not a hard one. By contrast, the outcome-based logic – i.e., “winning is (almost) all that matters” – that led the committee to seed Mississippi State #1 in their first three brackets is what kept Florida State alive. Of course that didn’t work out so well with Mississippi State. We suggest the committee is no more right about Florida State than they were about the Bulldogs, the season just ran out before it caught up with them.
Okay, so maybe this whole note is an “I told you so”. But it’s not about us. It’s about analytics, and better judgment. The committee had a very difficult job, made even moreso by the way things went this season. Let’s not pretend there is a right answer. And the committee was impressively less vulnerable to two of the biggest traps polls (and people!) fall into – outcome bias (e.g. over-emphasizing W/Ls) and anchoring and adjustment (e.g. insufficiently adjusting from earlier rankings). But they are handicapping themselves by eschewing good analytic tools. The more complicated the judgment, the more uncertain the world, the more people can benefit from a good model. Models are rarely perfect. Not even close. But models’ track record in college football is better than intution’s. Better even than experts’. And it will continue to be as long as those experts believe they can get everything there is to know from their own eyes.


